本篇的适读对象为了解MySQL, 需要使用并初次使用MySQL主从复制的群体. 主要介绍了MySQL主从复制环境搭建, 基于文件位置的主从复制的原理, 以及主从复制的应用场景及注意事项.
主从复制介绍
MySQL主从复制, 是MySQL提供的一套方案用于同步两个(或多个)数据库, 其中被同步的数据库是主库(Master), 保持同步的数据库是从库(Slave). MySQL通过将主库上发生的变动告知从库, 从库因此进行相同的操作, 来进行数据同步, 从而实现主从复制. 复制过程通过tcp进行, 在网络畅通的情况下是很快的.
使用MySQL主从复制可以完成很多功能, 例如一主一从(一个主库一个从库)进行数据库实时备份, 同时也可以分摊主库上压力, 将查询相关操作放到从库来进行, 进而又可以发展成一主多从(一个主库多个从库), 以应对在查询操作远多于修改操作的环境, 实现负载均衡. 这些功能在在应用到达一定规模后, 就很有必要的.
搭建主从复制环境
这里直接开始搭建主从复制环境, 使用的主从复制策略是基于文件+Position的方式, 这也是MySQL传统只从复制方式, 最新的有基于GTID的方式, 目前不讨论.
要实现主从复制需要两套MySQL数据库环境, 其中一套作为主库, 另一套作为从库. (这里我的测试环境主库从库均使用CentOS 8.02, MySQL 8.0.26, SQL语法使用的MySQL 5.7版本)
对于主库
1. 修改配置(/etc/my.conf)
# 修改主配置/etc/my.cnf [mysqld] ... server-id = 1 # 不可为0, 不可与从库server-id重复 log-bin = master_binlog # 将在data目录创建名为master_binlog.******的binary log log-bin-index = master_binlog.index # 将在data目录创建名为master_binlog.index的索引文件 sync-binlog = 1 # 设置binary log的刷新方式, 详见 主从复制数据安全性-从库配置 innodb-flush-log-at-trx-commit = 1 # 设置事务日志的刷新方式, 详见 主从复制数据安全性-从库配置 binlog-do-db = replication # 指定只记录数据库replication上的变动 # binlog-ignore-db = ... # 忽略相关数据库 binlog-format = MIXED # 设置binary log内容格式 ...
配置中, log-bin和log-bin-index都是配置的文件名, 主库启动后(MySQL服务启动)会在MySQL的data目录生成binary log和binary log index两份文件, 后者是用来管理前者的. MySQL通过log-bin配置知晓此数据库将为主库.
sync-binlog和innodb-flush-log-at-trx-commit是用来确保数据安全的, 最好都配1, 后面会解释这两个参数的含义.
默认的主从复制将复制所有的数据库, binlog-do-db用于指定在主从复制中主库关心的数据库或相对的使用binlog-ignore-db来忽略不关心的数据库. 其他还有些过滤方式这里就不列举了.
binlog-format设置binary log格式, 一般设置MIXED或者ROW最保险, 设置STATEMENT格式可能会遇到一些问题. 该参数后面会解释.
修改配置后需要重启MySQL服务, 使配置生效. 之后可通过SHOW MASTER STATUS查看主库信息, 有以下内容说明配置生效, 主库就已经准备好了.
mysql> SHOW MASTER STATUS; +----------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +----------------------+----------+--------------+------------------+-------------------+ | master_binlog.000001 | 468 | replication | | | +----------------------+----------+--------------+------------------+-------------------+
2. 创建从库需要使用的具有REPLICATION SLAVE权限的用户
从库使用主库用户来连接主库, 用户信息在从库将以明文的形式记录(包括密码). 因此最好为从库连接主库创建一个新的用户, 并使其只具有REPLICATION SLAVE权限.
mysql> CREATE USER 'replicas'@'%' IDENTIFIED BY 'replicas-password'; mysql> GRANT REPLICATION SLAVE ON *.* TO 'replicas'@'%';
3. 若主库已有数据, 则需要先拷贝并同步现有数据到从库
这里使用mysqldump拷贝主库结构和数据, 在拷贝数据期间需要锁定主库拒绝数据插入, 将数据导入从库并启动从库后方可解锁主库.
mysql> FLUSH TABLES WITH READ LOCK; # 主库锁定, 用于拷贝主库现有数据 # 拷贝已有的数据 [root@localhost ~]# mysqldump -p --databases replication > master_replication.sql # 导入数据到从库 mysql -p replication < master_replication.sql # 从库配置主库信息后启动 mysql> UNLOCK TABLES; # 解锁主库表
4. 从库启动后, 查看主库Dump线程
从库启动后, 通过SHOW PROCESSLIST查看主库进程列表, 有如下线程在运行就说明主从复制已经搭好了.
# 从库启动后, 此时主库查看PROCESSLIST, 发现多了用于主从复制的线程 mysql> SHOW PROCESSLIST; +----+-----------------+-------------------+-------------+-------------+------+-----------------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-----------------+-------------------+-------------+-------------+------+-----------------------------------------------------------------+------------------+ | 16 | replicas | 61.157.18.62:7435 | NULL | Binlog Dump | 4 | Source has sent all binlog to replica; waiting for more updates | NULL | +----+-----------------+-------------------+-------------+-------------+------+-----------------------------------------------------------------+------------------+
5. 主库上的一些其他操作
mysql> SHOW BINARY LOGS; # 查看当前所使用的binary log文件信息; 更进一步的, 可以使用 SHOW BINLOG EVETNS 来查看记录的事件
+----------------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+----------------------+-----------+-----------+
| master_binlog.000001 | 778 | No |
+----------------------+-----------+-----------+
mysql> SHOW SLAVE HOSTS; # 从主库查看从库一些信息
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 10001 | | 3306 | 1 | bb9d710e-143e-11ec-a8f6-000c29dacfe4 |
+-----------+------+------+-----------+--------------------------------------+
# 使用该语句清理不需要的binary log, 不要因为binary log占空间手动通过 rm 命令去删除文件
# !需要注意检查这些binary log是否所有的从库都已经不再需要, 若有必要对这些binary log进行备份
mysql> PURGE BINARY LOGS { TO 'log_name' | BEFORE datetime_expr };
# 重置主库, 将删除所有的binary log及binary log index文件, 重置主库状态, 创建一个新的binary log文件(编号从000001开始)
# !重置主库前, 确保先关闭所有从库(STOP SLAVE)并重置从库(RESET SLAVE), 确保从库与主库断开, 并且数据正常后, 方可执行该语句
mysql> RESET MASTER;
# 临时停止主库向binary log记录事件
mysql> SET sql_log_bin = ON;
对于从库
1. 修改配置(/etc/my.conf)
# 修改从库配置/etc/my.cnf ... [mysqld] ... server-id = 10001 # 不可为0, 不可与主库server-id相同 relay-log = replica_relaylog # 将在data目录创建名为replica_relaylog.******的relay log relay-log-index = replica_relaylog.index # 将在data目录创建名为replica_relaylog.index的索引文件 read-only = 1 # 从库只读 skip-slave-start = ON # 关闭从库自动启动, 使用START SLAVE手动启动 replicate-do-db = replication # 指定需要复制的数据库 # replicate-ignore-db = ... # 忽略不需要复制的数据库 # 其他一些表级别的控制(replicate-do-table, replicate-ignore-table) # 从库也可以使用 CHANGE REPLICATION FILTER 语句在运行期间施行过滤 # relay-log-recovery = ON # 崩溃重启恢复 ...
配置中, relay-log和relay-log-index和主库中log-bin, log-bin-index的作用相似, 从库启动后(此处是指施行START SLAVE语句)会在MySQL的data目录生成relay log和relay log index两份文件. 启动START SLAVE的数据库是从库.
read-only标识从库为只读的, 一般来说将重库置为可读, 放置意外对从库造成修改, 导致主库和从库数据不一致. 从库的改动可不能被复制到主库.
skip-slave-start用于控制从库不要在服务启动时自动连接主库, 而是通过START SLAVE来启动, 如果主从复制已经存在异常, 那应该不希望启动从库又报出重复的异常.
同样的在从库也可以选择只复制一些关心的库或者忽略一些不关心的库, 通过replicate-do-db/replicate-ignore-db, 同样的还有一些表级别的控制. 另外, 从库可以通过施行 CHANGE REPLICATION FILTER 语句在运行期间动态设置.
relay-log-recovery用于从库崩溃重启恢复relay log使用, 这里先注释掉了.
修改配置后需要重启MySQL服务, 使配置生效. 之后可通过SHOW SLAVE STATUS查看从库信息, 从输出可以看出配置已经生效了. 此时从库还并未启动, 还无法连接到主库.
mysql> SHOW SLAVE STATUS\G;
Slave_IO_State:
Master_Host: 118.31.38.50
Master_User: replicas
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: localhost-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File:
Slave_IO_Running: No
Slave_SQL_Running: No
Replicate_Do_DB: replication
... : ...
2. 连接到主库
从库的运行需要能够连接到主库, 执行CHANGE MASTER TO...语句配置主库信息(ip 端口 用户 密码)及主库binary log文件名及binary log文件的Position, 从库将从binary log的Position位置开始复制binary log的内容, 在操作主库时有提到, 这期间主库应该是被锁定只读的, 所以主库binary log的Position不会变动.
配置好主库的连接信息, 就可以执行START SLAVE启动从库了, 从库启动成功后再次使用SHOW SLAVE STATUS查看从库状态. 如下说是, 说明从库启动成功了.
# 配置主库信息, MASTER_USER需要具有REPLICATION SLAVE权限, 这里使用上面创建的replicas用户
# MASTER_LOG_FILE/MASTER_LOG_POS与主库SHOW MASTER STATUS内容一致
mysql> CHANGE MASTER TO MASTER_HOST='118.31.38.50', MASTER_USER='replicas', MASTER_PASSWORD='replicas.mysql',
-> MASTER_LOG_FILE='master_binlog.000001', MASTER_LOG_POS=468;
# 检查与主库信息匹配后, 启动从库
mysql> START SLAVE;
# 此时再通过SHOW SLAVE STATUS来查看从库状态, 有如下变化
mysql> SHOW SLAVE STATUS\G;
Slave_IO_State: Waiting for source to send event # 此处说明启动成功
Master_Log_File: master_binlog.000001
Read_Master_Log_Pos: 468
Relay_Log_File: localhost-relay-bin.000002
Relay_Log_Pos: 328
Relay_Master_Log_File: master_binlog.000001
Slave_IO_Running: Yes # I/O线程启动
Slave_SQL_Running: Yes # SQL线程启动
... : ...
# 从库查看PROCESSLIST, 发现多了两个用于主从复制的线程(I/O线程和SQL线程)
+----+-----------------+--------------------+-------------+---------+--------+----------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+--------------------+-------------+---------+--------+----------------------------------------------------------+------------------+
| 37 | system user | connecting host | NULL | Connect | 425 | Waiting for source to send event | NULL |
| 38 | system user | | NULL | Query | 424 | Replica has read all relay log; waiting for more updates | NULL |
+----+-----------------+--------------------+-------------+---------+--------+----------------------------------------------------------+------------------+
主从复制的环境搭建过程大致如此, 此时修改主库的replication库, 相应的操作将被记录到主库binary log文件, 从库通过获取该文件记录到自身relay log文件, 之后通过读取relay log, 同步主库replication库里的数据到自身的replication库, 默认情况下, 整个过程是异步的, 主库不会关心, 从库是否获取到数据, 从库也可以选择不立即同步所有的数据.
- 从库上的一些其他操作
# relay log无法直接打开查看, 可以通过SHOW RELAYLOG EVENTS查看. 该语句暂时没怎么用过 mysql> SHOW RELAYLOG EVENTS; # 可以临时停止从库的I/O线程, 此时从库不会再同步主库的binary log到本地relay log mysql> STOP SLAVE IO_THREAD; mysql> START SLAVE IO_THREAD; # 可以零食停止从库的SQL线程, 此时从库依然在同步主库的binary log到本地relay log # 但不会执行relay log中的事件, 这部分需要了解MySQL运行的原理, 便好理解了 mysql> STOP SLAVE SQL_THREAD; mysql> START SLAVE SQL_THREAD; # 重置从库, 将删除所有的relay log及relay log index文件,创建一个新的log及relay log文件(编号从000001开始) # RESET SLAVE 清理从库记录binary log的位置信息, 不会清理到主库的连接信息 # RESET SLAVE ALL 将清理所有从库元数据仓库信息(replication metadata repositories). mysql> RESET SLAVE [ALL]
整个过程如下图所示
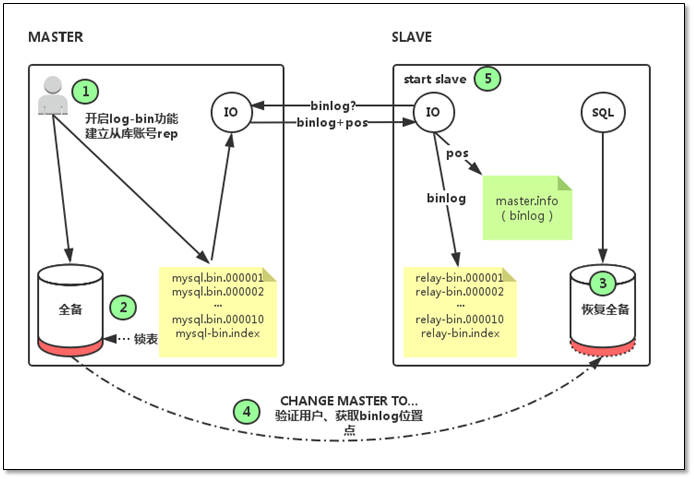
主从复制原理
如果按上面的操作搭建主从复制环境成功的话, 那么再来了解主从复制原理便简单了. 主从复制的运行需要依赖:
主库:
两个文件: binary log和binary log index文件, 用于记录主库数据库变动.
一个线程: 从库连接后, 启动Dump线程, 用于拷贝binary log数据到从库.
从库:
两个文件:relay log和relay log index文件, 用于接收主库binary log数据.
两个线程: I/O线程, 负责连接主库, 并向主库请求binary log数据. SQL线程, 负责执行relay log中的内容.
主库和从库通过tcp连接, 事件的记录和重放是基于文件进行的, 整个过程是异步的(主库不会关心从库是否同步数据成功).
主从复制的原理大致如此, 听起来比较简单, 但实际上也有比较细节性的东西需要考虑, 例如如何保证主从复制期间数据的安全, 主从复制效率太低, 延迟太高等问题, 这些细节部分可以说才是主从复制能够正常 正确运行的关键.
主从复制数据安全性
如何保证主从复制数据安全? 大致有一下几个方面需要考虑, MySQL也都已经提供了解决方案.
- 保证binary log文件数据自身的正确性.
- 保证relay log文件数据自身的正确性.
- 保证binary log中的内容与主库施行的操作完全一致.
- 保证relay log中的内容全部执行, 不得重复和遗漏.
- 主库崩溃恢复, 会发生什么? 会否影响binary log导致数据异常.
- 从库崩溃恢复, 会发生什么? 会否影响relay log导致数据异常.
下面展开讨论, 针对这些问题MySQL可以做的.
保证binary log文件数据自身的正确性
binary log事件校验
通常binary log记录事件长度和事件本身, 在读取binary log时通过长度截取. 可以在主库配置binlog-checksum为事件添加校验和, 在主库Dump thread读取binary log时启用master-verify-checksum来验证校验和.
binary log事件格式
binary log文件记录事件有三种格式: STATEMENT|ROW|MIXED. (binary log可以通过mysqlbinlog打开查看)
- STATEMENT(statement-based logging, SBL): 基于语句的格式, 此方式记录导致数据变化的sql语句.
优点: 日志文件小, 从而可以备份和恢复; 记录sql语句也便于数据异常时, 通过分析sql语句来找到蛛丝马迹.
缺点: 记录sql语句并不能保证数据一致, 例如sql语句使用RAND()函数, 这也是使用STATEMENT格式最大的缺陷 -- 数据不安全. - ROW(row-based logging, RBL): 基于行格式, 记录因操作导致受影响的的行(rows are affected).
优点: 数据安全, 所有变化的数据都会被记录.
缺点: 日志文件更大, 导致备份恢复都会更慢; 无法知道执行了那些操作, 只能通过mysqlbinlog --base64-output=DECODE-ROWS --verbose查看那些数据发生了变化. - MIXED(mixed logging): 混合以上两种格式, 默认使用STATEMENT格式记录, 无法判定为安全的SQL语句则回切换为ROW格式记录.
大多数情况下选用MIXED格式能够保证数据完整性同时兼顾性能.
(MySQL5.7之前默认使用statement-based, 5.7之后默认使用row-based)
保证relay log文件数据自身的正确性
relay log事件校验
在从库SQL thread通过启用slave-sql-verify-checksum验证由binary log复制到relay log后事件的校验和, 当然前提是binary log启用了binlog-checksum.
保证binary log中的内容与主库施行的操作完全一致
binary log"事务性"写入
对非事务表的修改在执行后立即存储在binary log中, 修改不能回滚. 如果操作提交一半, 或者在操作执行后写入binary log期间发生异常, 那么数据就不一致了. 但似乎这两种情况发生的几率很低? 不管如何都建议直接使用InnoDB使用事务来协助, 以免不必要的异常发生.
对事务表的修改(UPDATE、DELETE或INSERT)都会被缓存, 直到施行COMMIT语句. 此时会在执行COMMIT之前将整个事务写到binary log中. 如果COMMIT之前发生异常, 操作将被ROLLBAKC, 此时binary log还没有记录事件. 如果COMMIT操作成功, 那相关操作也就已经记录到binary log了. 这里可以看做是进行了"事务性"写入.
这里解释一下主库的两个配置: innodb-flush-log-at-trx-commit和sync-binlog
innodb-flush-log-at-trx-commit: 设置InnoDB在事务提交时刷新事务日志到文件的策略. (事务日志用于崩溃恢复.)
当innodb-flush-log-at-trx-commit=0时, 表示每隔1秒把事务日志刷新到文件. 意味着崩溃恢复可能会丢失1秒内的事务日志.
当innodb-flush-log-at-trx-commit=1时(默认), 表示在每进行以此事务提交都刷新一次事务日志到文件, 此时能够保证未提交的事务不会记录到binary log, 已提交的事务也全部记录到binary log.
当innodb-flush-log-at-trx-commit=2时, 表示在事务提交后1s刷新一次磁盘. 意味着可能会丢失1秒内的事务日志?
sync-binlog: 设置binary log文件刷新频率.
当sync-binlog=0时, 由操作系统自行处理何时刷新文件到磁盘. 意味着从库发生意外时, binary log可能会丢失一些条数据.
当sync-binlog=1时(默认), 事务每次COMMIT, binary log都会刷新文件到磁盘操作, 即每次COMMIT都能保证上一次的记录都已经保持到磁盘.
当sync-binlog=n时, relay log每从binary log同步n条事件, 才做刷新到磁盘操作, 意味着从库发生意外时, relay log会丢失n条数据.
innodb-flush-log-at-trx-commit和sync-binlog都置为1, 配合使用便能够保证, 在COMMIT时, 上一次的操作已经保存到磁盘, 即使崩溃也能够保证对已有的操作与binary log中的内容完全一致!
综上所述, 主库在记录binary log时, 可以通过校验和确保事件内容正确性(这一般不是必须的, 会增大文件和影响性能), 在对事务表修改之后, 在COMMIT前修改binary log文件, 尽最大可能确保了数据库内容和binary log内容一致, 最后通过ROW格式或者MIXED格式或在不使用STATEMENT格式的同时做一些"复杂"(被评定为不安全的)操作, MySQL能够保证主库事件被正确的记录到binary log.
保证relay log中的内容全部执行, 不得重复和遗漏
这里介绍一下主从复制的元数据仓库(replication metadata repositories):
从库启动依赖连接元数据仓库(connection metadata repository)和应用元数据仓库(applier metadata repository), 两者统称为从库元数据仓库(replication metadata repositories)
connection metadata repository: 记录了I/O线程连接主库和读取主库binary log的信息, 即CHANGE MASTER TO... 设置的那些东西.
配置master-info-repository={ TABLE | FILE }, 来指定数据记录到表(mysql.slave_master_info)还是文件(默认为data目录下master.info, 可以通过配置master-info-file指定).
mysql> SELECT * FROM mysql.slave_master_info\G;
*************************** 1. row ***************************
Number_of_lines: 32
Master_log_name: master_binlog.000001
Master_log_pos: 468
Host: 118.31.**.**
User_name: replicas
User_password: replicas.mysql
Port: 3306
...: ...
applier metadata repository: 记录了从库读取和执行relay log的信息.
配置relay-log-info-repository={ TABLE | FILE }, 来指定数据记录到表(mysql.slave_relay_log_info)还是文件(默认为data目录下relay-log.info, 可以通过配置relay-log-info-file指定).
mysql> SELECT * FROM mysql.slave_relay_log_info\G;
*************************** 1. row ***************************
Number_of_lines: 14
Relay_log_name: ./localhost-relay-bin.000006
Relay_log_pos: 207
Master_log_name: master_binlog.000001
Master_log_pos: 778
...: ...
这里关注的主要是applier metadata repository.
mysql.slave_relay_log_info表是InnoDB表, 它能够保证以事务的形式同时操作relay log中的事件和mysql.slave_relay_log_info表. 主要是Relay_log_pos字段, 能够保证relay log执行成功, 增加Relay_log_pos, 否则保持不变, 这样就能够保证relay log中的事件能够正确执行了.
主库崩溃恢复, 会发生什么? 会否影响binary log导致数据异常
由前面 保证binary log中的内容与主库施行的操作完全一致 可知
对于非事务表, 如果修改数据期间发生异常, 数据将无法回滚, 如果数据存在异常, 那么重启主库就需要人工介入了. 例如有10条插入语句应该都成功, 否则都失败, 此时只执行了5条插入, binary log也记录了5条, 那么重启后要么把已有的5条数据删除, 要么把剩下的5条数据补齐, 此期间的操作都会记录binary log.
对于事务表, 依赖于事务的崩溃恢复, 能够保证现有数据, 其之前的改动都被记录到binary log.
从库崩溃恢复, 会发生什么? 会否影响relay log导致数据异常
对于非事务表, 重启后如果数据异常则需要手动修复了, SHOW RELAYLOG EVENTS可能会有一些帮助吧.
对于事务表, 重启后崩溃前未完成的事务InnoDB会进行恢复, 恢复到applier metadata repository记录的Relay_log_pos位置后SQL thread继续执行.
这里解释一下主库的一个配置: relay-log-recovery
当从库在执行reply log期间异常崩溃, 重启从库时可以打开relay-log-recovery选项, 该选项是的从库会对relay log进行恢复, 通过applier metadata repository记录relay log位置的状态, I/O thread从该位置起, 重新从主库获取binary log数据, 确保relay log没有问题. 启用relay-log-recovery不是必须的, 除非认定了是relay log存在问题.
以上种种, 都表明了主从复制中, 无论主库还是从库, 使用InnoDB表的重要性, 它能为整个复制过程中, 数据保持正确提供很大的帮助.
其他可能
即使主库从库自身都完全没有任何问题, 还是有可能存在数据不一致的问题, 因为主库从库是异步复制(asynchronous replication). 例如主库记录事件到binary log, 从库还并未接收到此事件, 并且从库也标识relay log上已经没有最新的操作需要被执行, I/O线程也运行良好, 但实际上主库从库上数据并不一致!
延迟! 这是复制无法避免的, 又因为是异步的, 所以看上去主库从库在这个延迟期间, 都是最正常的表现, 却存在着不一样的数据. 解决这个问题只有使用某种同步方案, 让主库知晓从库已经接收到最新的改动了.
MySQL对此提供了一种同步策略: 半同步复制(semisynchronous replication), 使用半同步复制需要安装插件.
半同步主从复制: 主库在提交事务之前, 只需要至少一个从库收到了该事件, 主库方可提交事务. 半同步主从复制能够确保事件被发送到至少一个从库.
(对比全同步: 主库在提交事务之前, 事件传送到从库, 并且所有从库都提交该事务之后, 主库方可提交事务.)
大多数情况下异步复制也能工作的很好, 如果对数据安全性要求极高, 并且不在乎因为同步造成的性能影响, 那么可以使用 半同步复制. 这里就不在继续展开说明了.
主从复制的应用场景
备份(一主一从)
主从复制默认就可以看做是一种热备份策略(主库数据备份到从库), 只是需要注意:
- 对于在主库已有数据时, 启用主从复制需要先导出主库数据到从库, 再启动从库, 以保持主从数据完全一致.
- 在导出主库数据期间锁定主库, 禁止写入数据, 以免在导出的同时又有新数据写入, 从库导入数据后, 在解锁主库.
可以随时暂停从库, 做冷备份(mysqldump导出)而不影响主库运作(线上业务).
扩展(一主多从)
使用一主多从的策略做数据库扩展, 将写操作放到主句, 将读操作放到从库, 同时扩展从库数量做负载均衡.
此过程, 如那些操作由主库操作, 那些操作由从库操作, 如何做负载均衡则离不开程序上的支持, 这可能使访问数据库的逻辑变得相对复杂.
是否需要如此做数据库扩展根据实际业务判断, 如web服务, 用户大多数是在访问网页而不是修改后台数据, 那么使用该策略便极为合适了.
单点故障(主从切换)
主从切换: 使用主从复制解决数据库单点故障, 当主库意外无法提供服务时, 可以通过提升从库为主库来迅速恢复线上业务.
如果确定需要主从切换的操作, 那么需要:
1. 从库配置--log-bin, 并且注意不要启用log-slave-updates(该配置默认就没有启用)
从库配置log-bin意味着该从库也可以作为主库, 但默认的因为是从库的原因, 该从库还不会记录自身的事件到binary log, 除非启用log-slave-updates(启用该配置将导致从主句接收的binary log文件数据, 复制到relay log后被执行, 期间的操作又将被记录到从库自身的binary log文件中, 这里不需要这样).
2. 确保所有从库执行完了relay log中的所有内容, 方可进行主从切换. 停止所有从库I/O线程STOP SLAVE IO_THREAD后, 使用SHOW PROCESSLIST检查从库的运行, 如下状态说明从库已经执行了所有的relay log.
mysql> show processlist\G;
*********************** 3. row ***************************
...: ...
State: Replica has read all relay log; waiting for more updates
3. 从库切换主库, 执行STOP SLAVE->RESET MASTER
RESET MASTER将会启用一个新的binary log并且默认Position为4(此处有待验证), 其他从库连接新主库只需要通过CHANGE MASTER TO...设置新主库的ip端口, 用户密码即可, 不需要再指定binary log文件名(MASTER_LOG_FILE)和文件位置(MASTER_LOG_POS), 也不需要重启数据库.
4. 其他从库指向新主库后, 执行STOP SLAVE->CHANGE MASTER TO->START SLAVE即可.
5. 如果新主库设置了read-only, 关闭它.
若原主库恢复正常, 和上面的步骤相似, 切换当前主库为从库, 在重新连接到原主库.
使用主从复制注意事项
- 若是基于语句的(statement-based)复制, 需要注意主库从库是否同时支持执行该SQL语句. 这里实际上是数据库版本之间不兼容造成的, 一般来说由低版本向高版本复制是可行的, 但由高版本向低版本复制则可能出现更多问题. 不过不推荐使用基于语句的复制, 此方式需要注意的问题太多了!!
- 如果语句执行在主库和从库上发生了相同的错误, 那么错误会记录日志, 主从复制不会中断. 但如果在主库和从库出现了不同的错误, 那么主从复制会中断, 后续需要手动处理下一步如何进行. 可以使用slave-skip-errors配置跳过错误.
- 在主从复制环境, 不要手动操作从库的数据.
- 使用CHECKSUM TABLE table_name计算表的校验和, 通过校验和可以判断主库从库表及内容是否一致.
主从复制问题排查
如果主从复制没有正常工作, 那么可能:
- 主库未启用: 使用SHOW MASTER STATUS检查主库是否启用, 主库启用Position是非0的, 否则检查主句--log-bin选项.
- server_id不唯一: 主库和从库server_id冲突.
- 从库未工作: 使用SHOW SLAVE STATUS检查从库Slave_IO_Running和Slave_SQL_Running状态; 检查配置是否使用了skip-slave-start选项, 使用该选项需要手动执行START SLAVE才能启动从库.
- 主库和从库是否正常连接: 使用SHOW PROCESSLIST查看I/O线程和SQL线程的State. 如果无法正常连接, 那么查看主库从库之间网络能否ping通? 从库ip是否被限制? 从库连接主库用户是否有权限? 是否使用skip-networking禁用了网络?
如果语句执行在主库运行正常, 到从库却异常, 那么:
- 不要试图删除从库数据再从主库拷贝数据完整数据, 再启动从库. 这种方式可能不会成功.
- 试图找到从库异常的原因, 或者手动修复数据并跳过从库即将执行的语句后再启动从库.
mysql> SET GLOBAL sql_slave_skip_counter = N; # N的取值? 去官方文档里了解一下吧 mysql> START SLAVE;